
ما در آغاز یک دوران انقلابی زندگی میکنیم دلیل اون توسعه ی تجزیه و تحلیل داده ها، قدرت محاسباتی بزرگ و محاسبات ابری است. یادگیری ماشین قطعا نقش مهمی در اون ایفا خواهد کرد و مغزهای پشت این یادگیری ماشین ، مبتنی بر الگوریتم هستند.
این الگوریتم ها میتوانند به 3 دسته اصلی تقسیم بشند.
1.یادگیری با نظارت (Supervised Algorithms)
در این روش دیتاست (مجموعه ی داده ) تمرینی ما دارای ورودی و همچنین خروجی مناسب است.در طول جلسه یادگیری ماشین ، مدلی ایجاد میشود که متغیرهای آن را برای نمایش ورودی به خروجی متناظر تنظیم می کند.
2.یادگیری بدون نظارت (Unsupervised Algorithms)
در این دسته بندی هدفی برای تولید خروجی وجود ندارد بلکه الگوریتم های استفاده شده ، داده های ما را به گروه های مختلف دسته بندی میکنند.
3.یادگیری تقویتی (Reinforcement Algorithms)
این الگوریتم ها براساس تصمیم گیری آموزش دیده اند. بنابراین بسته به تصمیمات، الگوریتم ها خود را برای تولید خروجی موفقیت آمیز و یا شکست آموزش میدهند. در نهایت این الگوریتم دارای تجربه ای است که قادر به ارائه پیش بینی های خوب در یک موضوع خواهد بود.
الگوریتم هایی که قرار است توی این مقاله پوشش داده بشوند عبارتند از:
- رگرسیون خطی (Linear Regression)
- ماشین بردار پشتیبان (SVM (Support Vector Machine
- الگوریتم k نزدیک ترین همسایه (KNN (K-Nearest Neighbors
- رگرسیون لجستیک (Logistic Regression)
- درخت تصمیم (Decision Tree)
- الگوریتم خوشه بندی K-Means
- الگوریتم جنگل تصادفی (Random Forest)
- الگوریتم Naive Bayes
- الگوریتم های کاهش ابعاد (Dimensional Reduction Algorithms)
- الگوریتم های گرادیان تقویتی (Gradient Boosting Algorithms)
1.رگرسیون خطی (Linear Regression)
الگوریتم رگرسیون خطی ، از نقاط داده برای یافتن بهترین خط مناسب جهت مدل سازی داده ها استفاده می کند. یک خط را می توان با معادله y = m * x + c نشان داد که در آن y متغیر وابسته و x متغیر مستقل است. برای پیدا کردن مقادیر m و c با استفاده از دیتاست داده شده، از اصول محاسبات ریاضی پایه (عمومی) استفاده می شود.
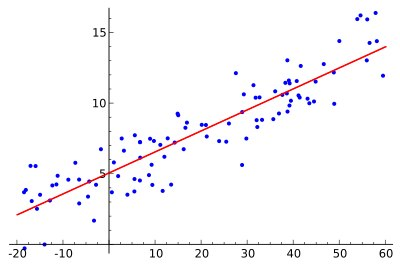
رگرسیون خطی دارای 2 نوع است که عبارتند از :
رگرسیون خطی ساده که تنها از یک متغیر مستقل استفاده می کند.
رگرسیون خطی چندگانه که متغیرهای مستقل مختلف برای آن تعریف می شود.
استفاده از “scikit-learn” یک ابزار ساده و کاربردی است که برای یادگیری ماشین در پایتون استفاده می شود.
2.ماشین بردار پشتیبان (SVM (Support Vector Machine
این مورد به نوعی از الگوریتم ها که جهت طبقه بندی ( classification) استفاده میشوند تعلق دارد. الگوریتم نقاطی از داده را با استفاده از یک خط جدا خواهد کرد. این خط جدا کننده بطوری انتخاب شده است که نزدیک ترین خطی باشدکه بین دو دسته انتخاب شده اند.
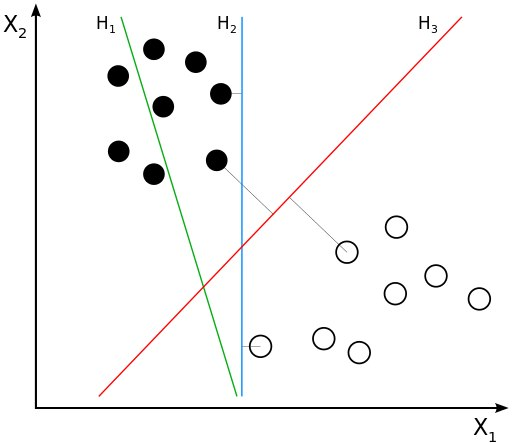
در نوشته بالا خط قرمز بطوری انتخاب شده است که بهترین خط باشد و داده ها را براساس فاصله شان نسبت به خط ، به دو دسته مجزا تقسیم کرده است.
3.الگوریتم k نزدیک ترین همسایه (KNN (K-Nearest Neighbors
این یک الگوریتم ساده است که نقاط داده ای ناشناخته را با نزدیک ترین k همسایگان خود پیش بینی می کند. مقدار k در اینجا در مورد دقت پیش بینی ها ، یک عامل حیاتی است. با محاسبه فاصله از طریق توابع پایه ای از قبیل هندسه اقلیدسی، نزدیکترین فاصله را تعیین می کند.
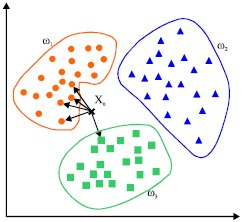
با این وجود این الگوریتم نیاز به قدرت محاسباتی بالا دارد و ما باید داده های ورودی را نرمال سازی کنیم تا هرکدام از نقاط داده در یک محدوده خاص قرار گیرند.
4.رگرسیون لجستیک (Logistic Regression)
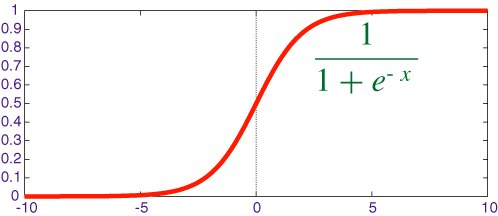
رگرسیون لجستیک زمانی مورد استفاده قرار می گیرد که در آن خروجی تمیز داده شده باشد و از جمله وقوع برخی رویدادها انتظار می رود (به عنوان مثال پیش بینی می کند که آیا باران رخ می دهد یا نه). معمولا، رگرسیون لجستیک از تابع برای فشردن مقادیر داده به محدوده خاصی استفاده می کند.
تابع “Sigmoid” یکی از همین توابعی است که حالت منحنی S شکل دارد و برای دسته بندی دوتایی مورد استفاده قرار میگیرد.این تابع مقداری بین محدوده 0 تا 1 را پوشش میدهد که میتواند به عنوان احتمال وقوع بعضی از رخدادها لحاظ شود.
y = e^(b0 + b1*x) / (1 + e^(b0 + b1*x))
معادله بالا یک رگرسیون منطقی ساده است که b0، b1 ثابت هستند.مقادیر یادگیری برای این نقاط طوری محاسبه می شود که خطای بین پیش بینی و مقدار واقعی حداقل باشد.
5.درخت تصمیم (Decision Tree)
این الگوریتم جمعیت را برای چندین مجموعه بر اساس برخی خصوصیات انتخاب شده (متغیرهای مستقل) یک جمعیت طبقه بندی می کند. معمولا این الگوریتم برای حل مشکلات طبقه بندی استفاده می شود. طبقه بندی با استفاده از برخی از تکنیک های مانند Gini, Chi-square, entropy و غیره انجام می شود.
اجازه دهید جمعیت مردم را در نظر بگیریم و از الگوریتم درخت تصمیم برای شناسایی افرادی که مایل به داشتن یک کارت اعتباری هستند استفاده کنیم. به عنوان مثال، سن و وضعیت تاهل را در نظر بگیرید که خواص این جمعیت است. اگر سن فرد بزرگتر از 30 سال باشد یا فرد ازدواج کرده باشد، مردم با در نظرگرفتن این خواص آیا تمایل دارند کارت های اعتباری را ترجیح دهند یا خیر؟
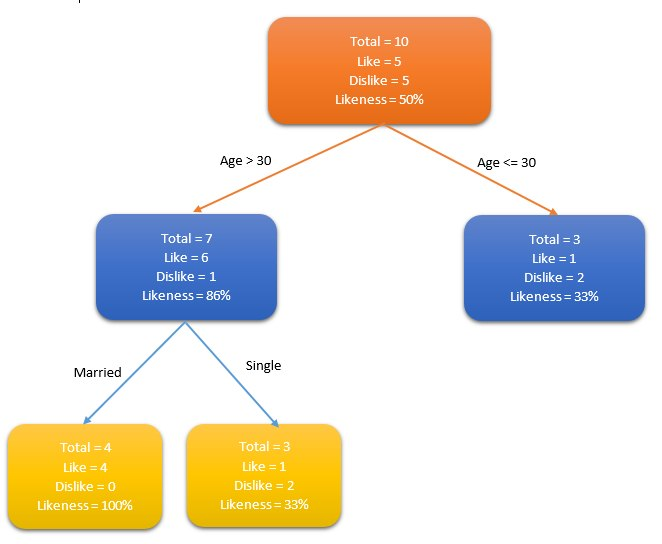
این تصمیم درخت را می توان با شناسایی خواص مناسب برای تعریف دسته های بیشتر گسترش داد. در این مثال، اگر یک فرد ازدواج کرده و بیش از 30 سال داشته باشد، بیشتر احتمال دارد که کارت اعتباری (با احتمال 100٪) داشته باشد. از داده های آزمایشی برای تولید این درخت تصمیم استفاده شده است.
6.الگوریتم خوشه بندی K-Means
این یک الگوریتم یادگیری بدون نظارت است که راهکاری برای مشکلات خوشه بندی ( clustering ) ارائه می کند.این الگوریتم به دنبال روشی برای ایجاد خوشه هایی است که حاوی نقاط داده همگن هستند.

مقدار k یک ورودی برای الگوریتم است. بر این اساس، الگوریتم k تعداد از مرکزثقل-گرانیگاه( centroid ) را انتخاب می کند. سپس داده های همسایه به ترکیب یک centroid دیگر با آن centroid اشاره می کند و یک خوشه ایجاد می کند. بعدها یک centroid جدید در هر خوشه ایجاد می شود. سپس داده ها در نزدیکی centroid جدید دوباره با یکدیگر ترکیب می شوند تا خوشه را گسترش دهند. این روند تا زمانی ادامه پیدا می کند که centroid ها تغییر نکنند.
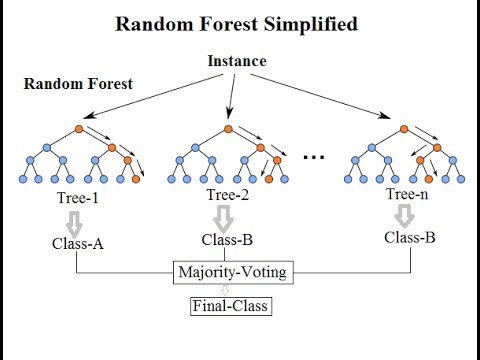
7.الگوریتم جنگل تصادفی (Random Forest)
جنگل تصادفی میتواند به عنوان مجموعه ای از درخت های تصمیم شناخته شود.هر درخت تلاش می کند یک طبقه بندی را تخمین بزند و این به عنوان “رای” نامیده می شود. در حالت ایده آل، ما هر رأی از هر درخت را در نظر می گیریم و بیشترین رای گیری را انتخاب می کنیم.
8.الگوریتم Naive Bayes
این الگوریتم بر اساس تئوری “Bayes” در احتمال است. با توجه به اینکه Naive Bayes را تنها وقتی میتوان اعمال کرد که مشخصه ها نسبت به یکدیگر مستقل باشند ، این در قضیه Bayes ضروری است. اگر ما سعی می کنیم یک نوع گل را با طول و عرض گلبرگ پیش بینی کنیم، می توانیم از رویکرد Bayes Naive استفاده کنیم چون هر دو ویژگی مستقل هستند.الگوریتم Naive Bayes همچنین در دسته طبقه بندی ( classification ) نیز جای میگیرد.این الگوریتم بیشتر زمانی استفاده می شود که کلاس های زیادی در مسئله وجود داشته باشد.
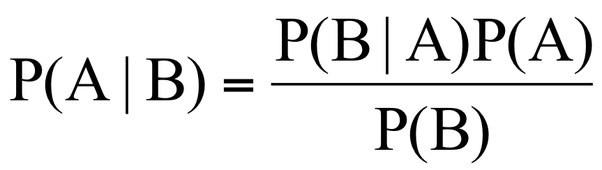
9.الگوریتم های کاهش ابعاد (Dimensional Reduction Algorithms)
بعضی از دیتاست ها ممکن است که متغیر های زیادی داشته باشند که این موضوع باعث سخت تر شدن کار با آنها می شود.به ویژه امروزه، اطلاعات جمع آوری شده در سیستم ها به دلیل وجود منابع بیش از اندازه ، در سطح بسیار دقیق رخ می دهد. در چنین مواردی، مجموعه داده ها ممکن است شامل هزاران متغیر باشد و اکثر آنها نیز غیر ضروری می باشند.
در این موارد، تقریبا غیرممکن است که متغیرهایی را که بیشترین تاثیر را در پیش بینی ما دارند را شناسایی کنیم. الگوریتم های کاهش اندازه در این نوع شرایط استفاده می شود.با استفاده از الگوریتم های دیگر مانند جنگل تصادفی و درخت تصمیم برای شناسایی مهم ترین متغیرها اقدام میکنیم.
10. الگوریتم های گرادیان تقویتی (Gradient Boosting Algorithms)
الگوریتم گرادیان تقویتی از الگوریتم های چندگانه ضعیف برای ایجاد یک الگوریتم دقیق تر استفاده می کند. به جای استفاده از یک تخمین زننده ، چندین الگوریتم پایدار و قوی تر خواهیم داشت.
الگوریتم های زیر چندین مورد از الگوریتم های گرادیان تقویتی هستند:
- الگوریتم XGBoost (از الگوریتم های liner و tree استفاده میکند )
- الگوریتم LightGBM (تنها از الگوریتم های tree-based یعنی مبتنی بر درخت استفاده میکند)
استفاده از الگوریتم های گرادیان تقویتی بیشتر بخاطر دقت بالای آنها است.علاوه بر این، الگوریتم هایی مانند LightGBM دارای عملکرد فوق العاده بالا نیز هستند.